
As a Marketing Ops professional, your role has many functions that contribute to the greater success of the organization.
But without an effective way to measure those contributions, it’s difficult to understand the full impact your work has on the business.
Stack Moxie’s founder and CEO, M.H. Lines, spoke at OpsStars last month to share her Strategic Quality Model, a framework for measuring (and improving) your organization’s foundation for trust and transparency among its teams. She broke down the value OKRs can bring to tracking the impact Marketing Ops has on your organization, from deriving the metrics that matter, to leveraging them to help advance your Marketing Ops career.
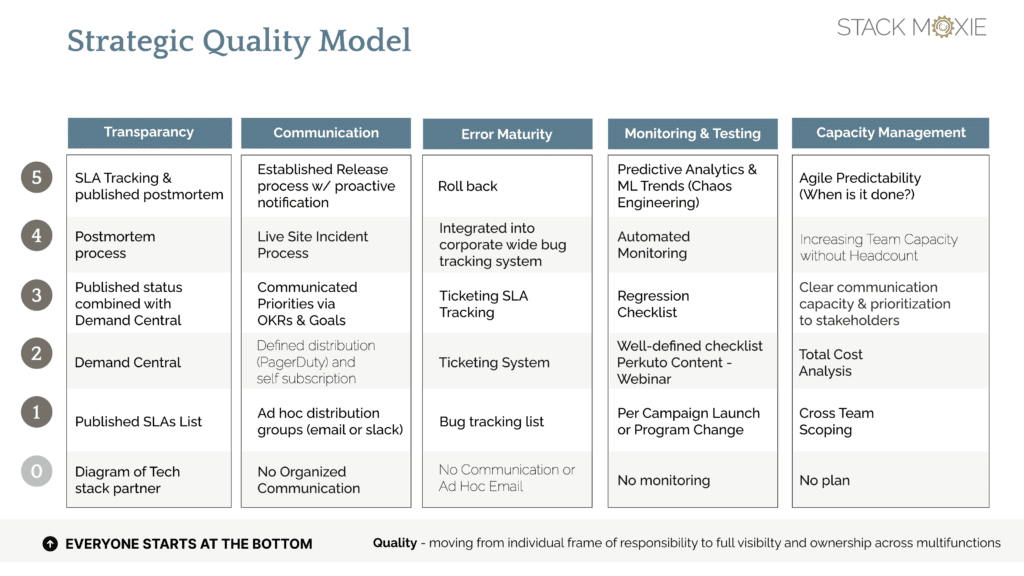
Transparency
From company hits and misses to deadline prioritization, being clear about the processes and team norms that have been established in your organization is the first step to fostering trust.
Diagramming your tech stack and creating your demand central
As your organization begins its journey to building quality, you can start with something as simple as creating a diagram of your tech stack that can be shared with employees so everyone is aware of the technologies and tools your efforts are built on.
From there, you should focus on growing transparency through clear expectations about deadlines, including a published list of SLAs that gives your teams the power to set and manage expectations about how and when things will be completed. Eventually, you can house all of this information in a Demand Central, a place accessible to all employees where they can find anything they might need to know about the status of projects or the tools they can use to help them.
Postmortem process and SLA tracking
Once your organization has established these fundamental resources, it is also important to build a postmortem process that can be utilized when something goes wrong, whether it’s a missed SLA or an outage that affects your users. This postmortem can start as something shared internally, but eventually, you should also strive to share some version of it with your users.
Having this transparency about when and how things have broken, and what steps your team has taken to fix them and prevent them from happening again, can be scary for your team at first. But, it is a powerful step to show customers and stakeholders that your organization is open about its errors and is taking action to improve, which does much more for trust than letting them discover outages on their own with no communication from your team.
Communication
Transparency and communication go hand in hand, which means it’s important to establish channels through which employees, customers, and investors can access information and learn about what’s going on at your organization. Many companies start without an organized way to communicate with these parties, which can create confusion and increase your team’s workload as they share information repeatedly with different individuals who come to them with questions.
Distribution lists and self-subscription
To prevent this, creating ad hoc distribution groups, either via email or Slack, allows you to reach all relevant individuals at once and quickly share information in a coordinated manner. You can segment messages into categories, and offer people the option to self-subscribe so that they can receive the alerts they want, and skip the rest. Giving individuals the power to choose what and how often they receive alerts helps them feel in control and in the loop, which goes a long way in building their trust.
Clear priorities via OKRs
Communication goes beyond sharing scheduled information with people, and includes clear conveyance of what your organization’s goals are and how a given team is responsible for helping reach them. Establishing OKRs is a great example of this type of communication, and helps keep your team on the same page about where it should focus its efforts.
Established live site incident process and release notifications
Finally, having established processes for communicating live site incidents and release updates to users and employees is a major milestone for an organization to achieve. These are sent proactively to alert parties to either errors or new releases, giving them time to prepare for potential impacts that these events may have on their work.
Error maturity
Perhaps one of the most difficult parts of managing your team is dealing with breakages and errors. This situation creates stress for your entire organization, and can make it difficult to be truly transparent with users. However, building your error maturity not only makes communication about issues easier, but also helps prevent errors from recurring and striking twice.
Choosing not to communicate errors
The first level of error maturity is to not communicate errors at all; many teams choose to do this in order to prevent drawing unnecessary attention to an issue that the organization is already aware of and actively trying to fix, or that was fixed quickly.
Although this may seem like a way to protect your organization’s track record, it can actually do more harm than good. It is likely that at least a subset of your users noticed the issue, and by choosing not to speak about it or make an announcement, it can leave the impression that your team prefers to hide things rather than being open about them. This leaves the door open for customers to wonder what else is happening behind the scenes that they’re unaware of.
Worse yet, an unacknowledged error may prompt users to announce them on your behalf, like via a LinkedIn post, which takes away your opportunity to control the narrative and use the error as a way to prove that your team is capable of dealing with issues confidently.
Bug tracking list, integrated ticketing system with SLAs, and roll-back feature
Rather than waiting for errors to inevitably happen, having processes in place that define what a response should look like takes the burden off your team to decide how to handle it. A bug tracking list gives your organization an internal way to know if errors are happening and confirm that the engineering team is aware of them and dealing with them.
Not only does this help your entire organization keep track of the status of certain parts of your platform, but it also saves time for your engineers. They will no longer need to respond to each person who messages them to report the issue, since it will be clear from the bug tracking list that the error has been noticed and the engineering team is already taking action.
Similarly, having a company-wide ticketing system where everyone goes to report issues they may find helps foster transparency regarding what issues your product or platform may be facing. It’s crucial for the same ticketing system to be used across teams in order to ensure errors and outages are communicated across the organization, and once again prevents the same issues from being reported multiple times on different platforms.
When combined with a published SLAs list, you can use your ticketing system to give team members an idea of when they can expect errors to be resolved. It also makes it easier for customer-facing employees to communicate with external individuals about what impact breakages may have on their work and what they can expect from your organization to fix it.
The final stage of error maturity is to implement a roll-back feature, which allows the system to be returned to a previous version in case something goes wrong during a new release. This capability is aspirational for most organizations, but is something you can work towards achieving in order to stop errors that arise from system changes from impacting users.